
A customer came to CloudFIrst and asked if we could help get their output queues cleaned up. They had a compliance requirement to keep one year’s worth of critical spool files on the system but needed a means to clear out everything else.
They had asked if there was a way to automate the process so that it ran reliably every day. In this article I will share the solution and step-by-step process we developed that helped the customer solve this unique challenge.
The Aha! Moment
Over the last few years, I have found that the IBM POWER team keeps releasing more and more exciting SQL tools with each technology refresh. I found what I was looking for to help address the customer’s issue when I located the table QSYS2.OUTPUT_QUEUE_ENTRIES.
Here is where I discovered how we could capture critical spool file attributes for a specific output queue. More information on this table can be found here: https://www.ibm.com/docs/en/i/7.2?topic=services-output-queue-entries-table-function.
SQL Table QSYS2.OUTPUT_QUEUE_ENTRIES to the Rescue
First, I opened up a “Run SQL Scripts” session in Access Client Solutions to come up with this SQL statement (circled) that displays all of the spool files in a specific output queue that were older than one year (365 days). (Job names redacted for privacy).
Points to note in the SQL statement:
- QSYS2.OUTPUT_QUEUE_ENTRIES (‘QGPL’, ’QPRINT’, ’*NO‘) shows the information found in output queue QPRINT in library QGPL. Since we only want to see the summary information and not detailed information, the default was left at *NO.
- The field CREATE_TIMESTAMP is the date the spool file was created. To view spool files that are older than one year – this is where the CREATE_TIMESTAMP < CURRENT DATE – 365 days rule comes into play.
After running this script, I was amazed to learn there were 39,000 print jobs that could be removed from the system!
This worked, but I needed to dump these results into a work file – this would allow me to spin through the records in a CL program. I came up with this SQL statement (circled) to put the spool file header information into a work file.
Let’s jump back to our SQL Script window again:
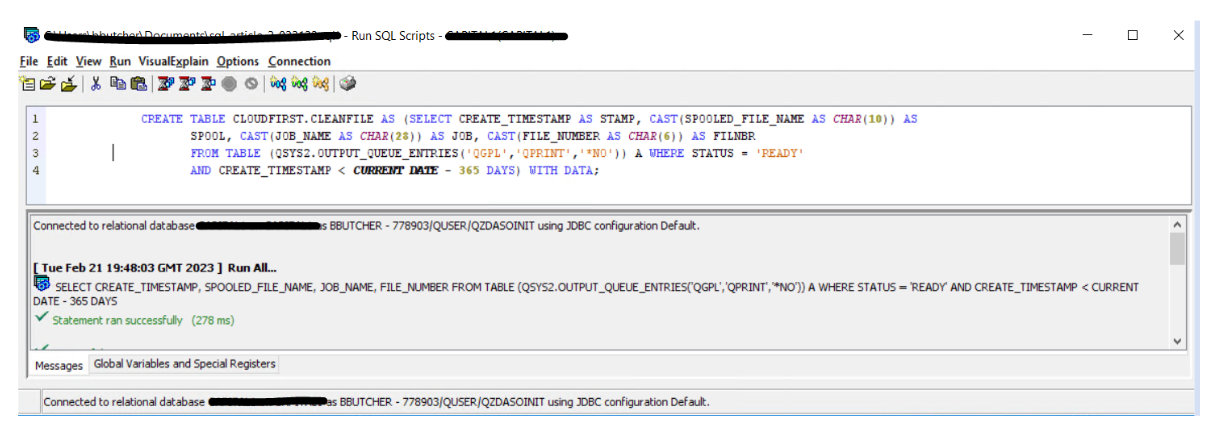
Now we are taking the contents and putting it into a file called CLOUDFIRST/CLEANFILE. The field names were changed to be in the correct format. In this process we are capturing and formatting the spool file name, the job name (including the job, user, and job number), and the file number. This data will then be plugged into the DLTSPLF (Delete Spool File) command.
Putting RUNSQL and DLTSPLF Commands to Work To Remove Spool Files
The CREATE TABLE SQL statement above is in the “Run SQL Scripts” GUI interface in Access Client Solutions. But this can also be coded by running the exact same statement in the RUNSQL command in a CL. Just pass in your output queue name, output queue library, and days to keep spool files. Use a few *CAT operators to glue the statement together and you are ready to proceed. In my CL, it looks something like this:

Next, run it in the RUNSQL command as scripted below:
RUNSQL SQL(&MYSQL COMMIT(*NONE) NAMING(*SQL)
When this gets run in the CL program, the data that is stored in my work file, and the record on the POWER system, should look like this:
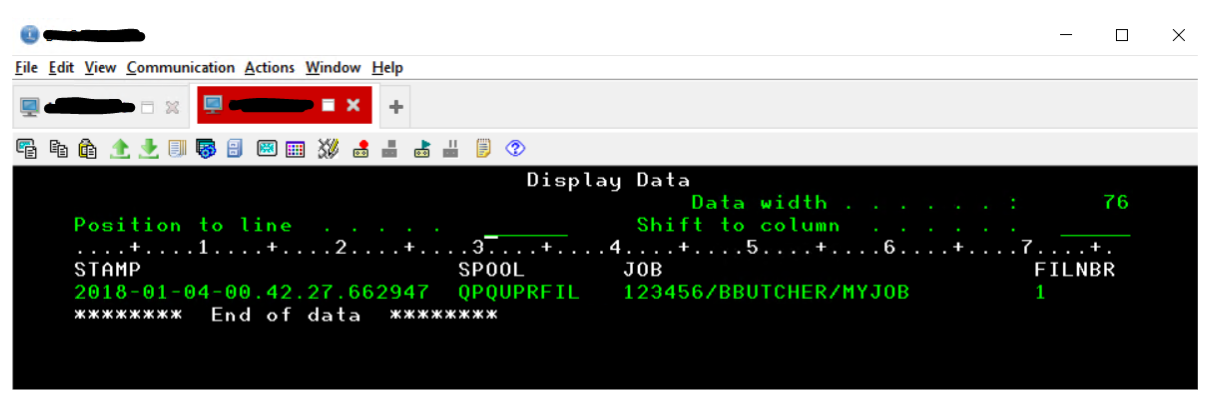
With the information above, I then plug the fields into a Delete Spool File command (DLTSPLF) to delete the spool file. I can just read my record and concatenate it into the FILE, JOB and FILRNBR parameters of the DLTSPLF command, shown below:
DLTSPLF FILE(QPQUPRFIL) JOB(123456/BBUTCHER/MYJOB) FILENBR(1)
Next, I used the QCMDEXC API to run the DLTSPLF statement and pass through all the records in my work file CLOUDFIRST/CLEANFILE.
Putting together a loop in your CL program allows you to cycle through all the spool files discovered when you executed the RUNSQL command – powerful stuff.
Final Thoughts
In summary, we built this CL program to do the following to meet our client’s objective:
- Pass in 4 parameters:
- Output queue name
- Output queue library
- How many days’ worth of spool files to keep on the system
- Delete Flag – do you want to delete the spool files, or only find the number of spool files that would be flagged to be removed
- Build the work file CLOUDFIRST.CLEANFILE using the RUNSQL command and passing in the output queue, output queue library, and the number of days’ worth of spool files to keep.
- Read through all of the entries in the work file.
- If the flag is set to delete, execute the DLTSPLF command with the QCMDEXC API
- If the flag is set to not delete, send a message to the user of the number of spool files that match the criteria
- Capture the date and time of what output queue was flagged to be cleaned up, and how many spool files were removed if the delete flag was enabled.
To enable this workflow, I ended up creating a command called CLEANQ which accepts the four parameters defined above – output queue, output queue name, days’ worth of spool files to keep, and delete flag.
I then created a separate file called QUEUE which holds all of the output queues the customer wants cleaned up.
Next, I created a CL program that reads through the QUEUE file and then executes the CLEANQ command to keep the customer’s critical spool files on the system, in this case files aged less than 365 days, and remove the rest.
Finally, I also added this CL to run daily in the IBM Job Scheduler.
I find myself going into Access Client Solutions often, and if you click on “Run SQL Scripts”, there is a treasure chest full of great information if you open “Insert From Examples.” It is amazing how much information you can capture from your systems with SQL. Even if you aren’t an SQL expert, the examples provided should help you understand how things work to extract, delete, or retain data to your unique requirements.
My hope is this article can help others who are trying to keep their spool files in check using SQL. If you need more assistance, please reach out to us at https://www.cloudfirst.host.
